Nếu bạn bắt đầu hành trình của mình trong thế giới xử lý dữ liệu hiện đại, Kafka sẽ là cái tên mà bạn bắt gặp rất nhiều khi tìm hiểu. Hãy cùng Tothost với những thông tin về Kafka qua bài viết này nhé!
Mục lục
Mục lục
1. Kafka là gì?
Apache Kafka (gọi tắt là Kafka) là một nền tảng phát trực tuyến sự kiện phân tán mã nguồn mở. Hiện nay, Kafka được phát triển bởi Apache Software Foundation và được viết bằng Java và Scala. Kafka được tạo ra để giải quyết những khó khăn trong việc xử lý lượng dữ liệu khổng lồ trong thời gian thực (real-time), cho phép các ứng dụng xuất bản, đăng ký, lưu trữ và xử lý các luồng bản ghi (streaming event).
Ban đầu, LinkedIn đã phát triển Kafka vào năm 2011 và sau đó được mở nguồn cho Apache Software Foundation. Những người đồng sáng lập phần mềm Kafka là Jay Kreps (CEO của Confluent), Neha Narkhede (cựu CTO của Confluent) và Jun Rao – một sự thật thú vị là cả ba người họ đều đồng sáng lập Confluent. Cái tên Kafka được lấy ý tưởng từ Franz Kafka – một nhà văn Đức vĩ đại ở thế kỉ 20. Cho tới nay, Kafka đã trở thành nền tảng stream dữ liệu phân tán hàng đầu, có khả năng nhập và xử lý hàng nghìn tỷ bản ghi mỗi ngày. Đến cả những tổ chức trong danh sách Fortune 500 cũng sử dụng Kafka để cung cấp trả nghiệm theo thời gian thực và dữ liệu cho khách hàng của họ. Một số cái tên có thể kể đến như AirBnB, Microsoft, Netflix, Target,…
1.2. Một số khái niệm liên quan
Producer: Là những ứng dụng tạo ra dữ liệu và đồng thời gửi dữ liệu này đến Server của Kafka. Dữ liệu này được định dạng và gửi đi dưới dạng mảng byte tới Server.
Consumer: Consumer đọc các tin nhắn từ một partition bất kỳ, cho phép người sử dụng mở rộng số lượng tin nhắn được sử dụng một cách tương tự như cách mà những producer cung cấp các tin nhắn.
Consumer Group: Những Consumer tổ chức thành các nhóm Consumer, sử dụng cho một chủ đề cụ thể, và mỗi consumer trong nhóm chỉ đọc tin nhắn từ một partition duy nhất.
Cluster: Kafka Cluster là một tập hợp các máy chủ, mỗi tập trong Cluster được gọi là một Broker.
Broker: Broker là một Kafka Server, đóng vai trò là cầu nối giữa Message Publisher và Message Consumer để hai thành phần này có thể trao đổi tin nhắn với nhau.
Topic: Dữ liệu được truyền trong Kafka theo định dạng chủ đề (topic). Khi cần truyền dữ liệu cho các ứng dụng riêng biệt, ta sẽ tạo ra các chủ đề khác nhau tương ứng.
Partitions: Trong trường hợp một chủ đề nhận nhiều hơn số tin nhắn quy định trong cùng một khoảng thời gian, chúng ta có thể chia chủ đề này thành các partition được chia sẻ giữa các máy chủ trong Cluster để xử lý những tin nhắn này. Các partition sẽ hoạt động độc lập và có số lượng phù hợp với nhu cầu của ứng dụng.
Zookeeper: Được sử dụng trong việc quản lý và triển khai các Broker.
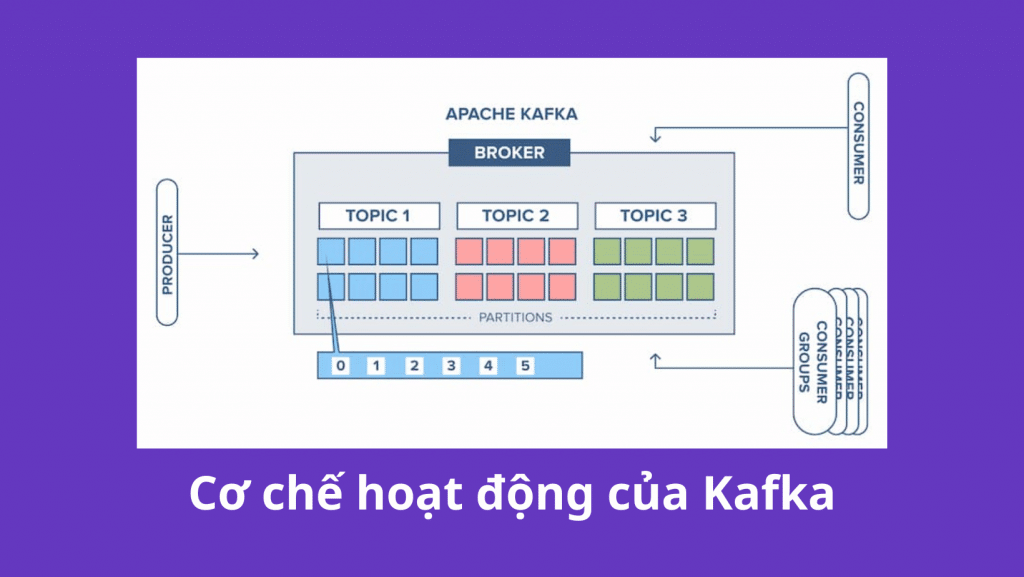
2. Cơ chế hoạt động của Kafka
Kafka hoạt động dựa trên sự kết hợp của hai mô hình chính, đó là hàng đợi (queing) và xuất bản-đăng ký (publish-subscribe, hay viết tắt là pub-sub). Trong đó:
Mô hình queing cho phép dữ liệu được xử lý phân tán trên nhiều người tiêu dùng và tạo ra khả năng mở rộng cao.
Mô hình pub-sub tiếp cận cùng một lúc nhiều người đăng ký, và các tin nhắn sẽ được gửi đến nhiều người đăng ký; tuy nhiên, mô hình này không thích hợp để phân tán công việc cho nhiều người làm.
3. Vai trò của Kafka
3.1. Chức năng như một trung tâm truyền thông
Người dùng có thể sử dụng Kafka như một giải pháp thay thế cho các trung tâm truyền thông như ActiveMQ hoặc RabbitMQ.
3.2. Quản lý hoạt động trang web
Một cách sử dụng truyền thống của Kafka là trong việc xây dựng và quản lý các trang web, nơi nội dung được cập nhật theo thời gian thực. Các dữ liệu như lượt xem trang và hoạt động tìm kiếm được tổ chức thành các chủ đề. Quản lý hoạt động này giúp phân tích hành vi của người dùng trang web một cách hiệu quả, từ đó thu hút và giữ chân độc giả.
3.3. Đo lường
Kafka cũng có thể được sử dụng để xây dựng hệ thống đo lường các hoạt động, tức là tập hợp dữ liệu thống kê từ nhiều nguồn phân tán trên trang web để tạo ra một nguồn dữ liệu tổng hợp.
3.4. Tạo log
Kafka hỗ trợ việc tạo ra các log hoặc nhật ký hoạt động, tóm tắt chi tiết và cung cấp bản ghi chính xác về dữ liệu sự kiện để phục vụ cho việc xử lý trong tương lai.
3.5. Xử lý dữ liệu theo thời gian thực
Xử lý dữ liệu theo thời gian thực là một ứng dụng phổ biến của Kafka.. Hệ thống này được phát triển để xử lý dữ liệu ngay khi nó được thêm vào chủ đề, và sau đó truyền đến bên nhận dữ liệu. Điều đặc biệt là, thư viện Kafka Streams được tích hợp từ phiên bản 0.10.0.0, mang đến khả năng xử lý dữ liệu theo thời gian thực một cách nhẹ nhàng và mạnh mẽ.
4. Ưu và nhược điểm của Kafka
4.1. Ưu điểm
Sau đây là một số ưu điểm nổi bật của Kafka:
Khả năng mở rộng: Kiến trúc phân tán đem lại khả năng mở rộng nhanh chóng mà không làm gián đoạn hoạt động. Khả năng mở rộng của nó thông qua việc phân phối các phân vùng trên các máy chủ khác nhau.
Độ bền cao: Quá trình sao chép dữ liệu của Kafka được đảm bảo do sao chép trên nhiều broker, ngăn chặn mất mát dữ liệu ngay cả khi có lỗi xảy ra mở mức broker. Với việc tuân thủ nguyên tắc append only commit log, Kafka commit log cung cấp độ bền, khả năng chống lỗi và xử lý thông báo một cách hiệu quả.
Xử lý theo thời gian thực: Kafka cung cấp khả năng truyền và xử lý dữ liệu theo real-time tuyệt vời phù hợp cho các ứng dụng đòi hỏi truyền dữ liệu có độ trễ thấp.
Mã nguồn mở (Open-source): Kafka là phần mềm mã nguồn mở, do đó có thể chỉnh sửa, tuỳ chỉnh và mở rộng chức năng tự do theo yêu cầu cụ thể.
Khả năng tương thích nhiều nền tảng cùng nhiều công cụ và thư viện khác nhau, tạo ra một hệ sinh thái đa dạng.
4.2. Nhược điểm
Bên cạnh những ưu điểm là một số nhược điểm như:
Thiếu công cụ giám sát: Kafka không có bộ công cụ giám sát và quản lý đầy đủ. Để khắc phục điều này, có thể sử dụng các công cụ từ bên thứ ba như Kafka Monitor (được phát triển bởi LinkedIn), Datadog và Prometheus để theo dõi. Ngoài ra, còn nhiều tùy chọn mã nguồn mở và thương mại khác cũng có sẵn.
Phụ thuộc vào Zookeepers: Trong những phiên bản trước của Kafka, đã có sự phụ thuộc vào Apache ZooKeeper để điều phối cụm, điều này tăng thêm độ phức tạp và tạo ra các điểm lỗi tiềm ẩn.
Phức tạp trong Cài đặt, Cấu hình và Quản lý: Tính phân tán tự nhiên của Kafka có thể gây ra sự phức tạp trong việc thiết lập, cấu hình và quản lý, đòi hỏi sự chuyên môn để triển khai và duy trì một cách hiệu quả.
Yêu cầu Tài nguyên Đáng kể: Việc quản lý các cụm Kafka đòi hỏi một lượng tài nguyên phần cứng đáng kể, bao gồm bộ nhớ, dung lượng lưu trữ và băng thông mạng.
Xử lý chưa linh hoạt: Đôi khi số lượng queues trong Cluster của Kafka tăng lên, hệ thống có hiện tượng xử lý chậm chạp và kém nhạy bén hơn.
Kết luận
Như vậy, qua bài viết “Những thông tin cơ bản về Kafka” Tothost hy vọng rằng đã giúp bạn có được thêm kiến thức bổ ích và đây có thể sẽ là cái tên hỗ trợ đắc lực của bạn trong công việc sau này. Bạn có thể theo dõi thêm các bài viết liên quan của Tothost:
Khi bạn click vào một bài viết, chốt thành công một đơn hàng trên Shopee hay đăng nhập vào Facebook, mọi thứ dường như diễn ra mượt mà chỉ trong chớp mắt. Thế nhưng, ẩn sau giao diện bóng bẩy đó là một hệ thống xử lý dữ liệu khổng lồ đang hoạt động hết công suất. Thế giới Web hiện đại được vận hành dựa trên sự giao tiếp liên tục của hai "bán cầu": Server-side (phía máy chủ) và Client-side (phía máy khách). Bài viết này sẽ giúp bạn giải mã Server-side là gì, cũng như hiểu rõ sự khác biệt mang tính "sống còn" giữa hai đầu cầu này trong quy trình phát triển và tối ưu Website.
Bất kể bạn đang vận hành một website doanh nghiệp, một hệ thống app nội bộ hay đang cắm tool MMO, rủi ro mất dữ liệu luôn hiện hữu. Máy chủ có thể bị tấn công Ransomware, lỗi cấu hình phần mềm, hoặc đơn giản nhất là... bạn lỡ tay gõ nhầm lệnh xóa. Việc sao lưu (Backup) dữ liệu định kỳ là chiếc phao cứu sinh duy nhất. Bài viết này sẽ hướng dẫn bạn chi tiết từ A-Z cách Backup và Restore dữ liệu trên cả VPS Linux và VPS Windows, cùng những lưu ý "sống còn" dành riêng cho khách hàng sử dụng dịch vụ tại TotHost.
Trong bối cảnh không gian địa chỉ IPv4 ngày càng cạn kiệt, làm thế nào để hàng tỷ thiết bị trên toàn cầu có thể kết nối Internet một cách thông suốt và an toàn? Câu trả lời nằm ở NAT (Network Address Translation) – một công nghệ định tuyến "xương sống" không thể thiếu trong bất kỳ hệ thống mạng máy tính hay hạ tầng máy chủ nào hiện nay. Vậy thực chất NAT là gì? Công nghệ này vận hành ra sao và bao gồm những chuẩn phân loại nào? Bài viết dưới đây sẽ giúp bạn giải mã chi tiết toàn bộ các khái niệm, nhiệm vụ cốt lõi và những thuật ngữ kỹ thuật quan trọng nhất liên quan đến NAT.
Hiện nay, các dịch vụ điện toán đám mây dần trở nên phổ biến với mọi Doanh Nghiệp. Chính vì vậy, ngày càng xuất hiện nhiều lựa chọn đa dạng hơn như: Public Cloud, Private Cloud, Hybrid Cloud. Trong nội dung bài viết này, Tothost sẽ giải thích chi tiết Hybrid Cloud là gì cùng những lợi ích khi sử dụng mô hình này. Hãy cùng theo dõi nhé!
CloudFlare không còn là cái tên xa lạ đối với các quản trị viên website. Nó giúp cho website tăng tốc độ truy cập, mang đến sự bảo mật cao, và tiết kiệm băng thông cho máy chủ. Vậy, thực chất CloudFlare là gì? Thiết lập và cài đặt CloudFlare như thế nào?
Cho dù bạn có biết đến các thuật ngữ như Cloud, Cloud storage, Cloud computing hay không. Thì mỗi ngày, mỗi giờ, bạn vẫn đang tiếp xúc với chúng một cách vô thức. Những khái niệm tưởng chừng xa lạ nhưng lại gắn liền với đời sống thường nhật của bạn. Vậy, chính xác Cloud storage là gì? Chúng vận hành ra sao, ảnh hưởng thế nào đến cuộc sống của chúng ta? Bạn hãy cùng TotHost tìm hiểu qua bài viết sau nhé!