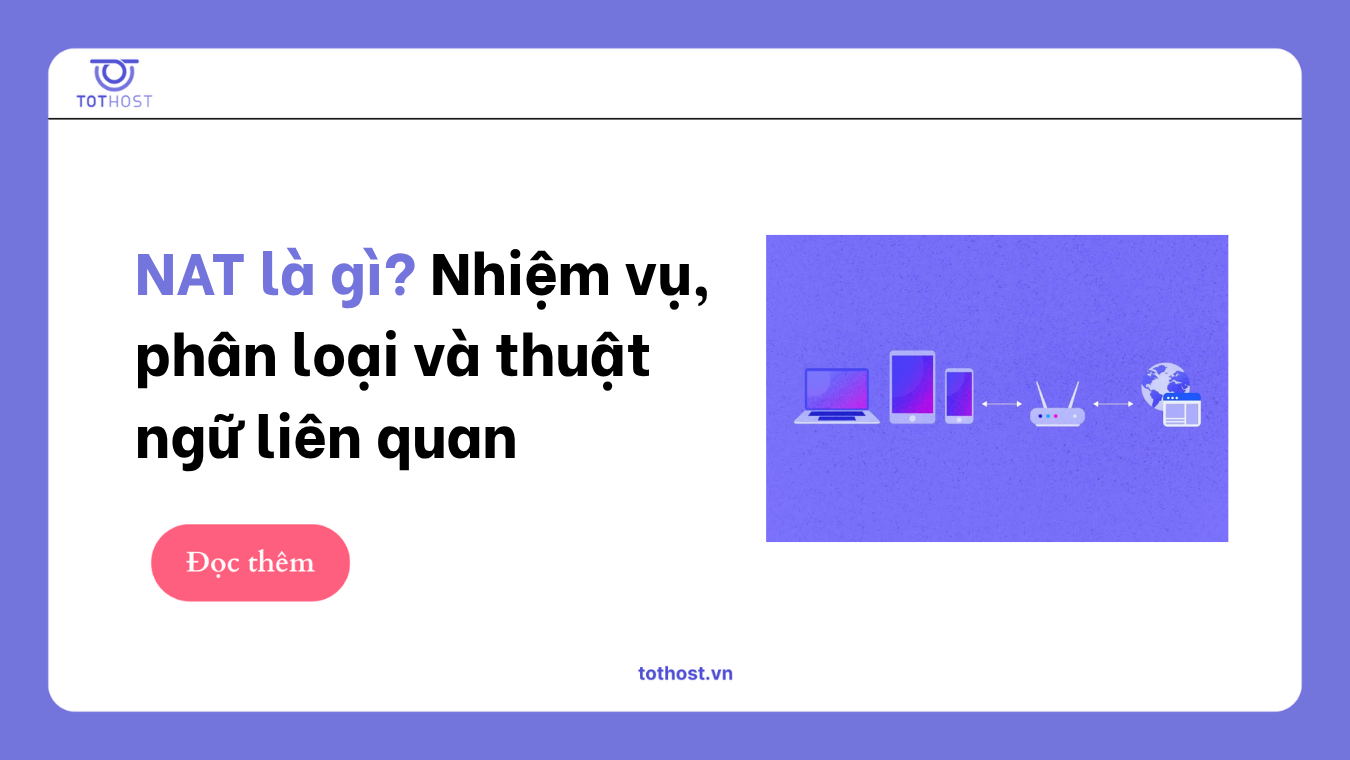
Trong bối cảnh không gian địa chỉ IPv4 ngày càng cạn kiệt, làm thế nào để hàng tỷ thiết bị trên toàn cầu có thể kết nối Internet một cách thông suốt và an toàn? Câu trả lời nằm ở NAT (Network Address Translation) – một công nghệ định tuyến "xương sống" không thể thiếu trong bất kỳ hệ thống mạng máy tính hay hạ tầng máy chủ nào hiện nay. Vậy thực chất NAT là gì? Công nghệ này vận hành ra sao và bao gồm những chuẩn phân loại nào? Bài viết dưới đây sẽ giúp bạn giải mã chi tiết toàn bộ các khái niệm, nhiệm vụ cốt lõi và những thuật ngữ kỹ thuật quan trọng nhất liên quan đến NAT.
Hiện nay, các dịch vụ điện toán đám mây dần trở nên phổ biến với mọi Doanh Nghiệp. Chính vì vậy, ngày càng xuất hiện nhiều lựa chọn đa dạng hơn như: Public Cloud, Private Cloud, Hybrid Cloud. Trong nội dung bài viết này, Tothost sẽ giải thích chi tiết Hybrid Cloud là gì cùng những lợi ích khi sử dụng mô hình này. Hãy cùng theo dõi nhé!
CloudFlare không còn là cái tên xa lạ đối với các quản trị viên website. Nó giúp cho website tăng tốc độ truy cập, mang đến sự bảo mật cao, và tiết kiệm băng thông cho máy chủ. Vậy, thực chất CloudFlare là gì? Thiết lập và cài đặt CloudFlare như thế nào?
Cho dù bạn có biết đến các thuật ngữ như Cloud, Cloud storage, Cloud computing hay không. Thì mỗi ngày, mỗi giờ, bạn vẫn đang tiếp xúc với chúng một cách vô thức. Những khái niệm tưởng chừng xa lạ nhưng lại gắn liền với đời sống thường nhật của bạn. Vậy, chính xác Cloud storage là gì? Chúng vận hành ra sao, ảnh hưởng thế nào đến cuộc sống của chúng ta? Bạn hãy cùng TotHost tìm hiểu qua bài viết sau nhé!