File Robots.txt là gì? Cách tạo tệp Robots.txt đơn giản nhất cho Website 2024
03/10/2023
Robots.txt có chức năng giúp cho trình thu thập dữ liệu của những công cụ tìm kiếm nắm được khả năng yêu cầu thu thập dữ liệu từ website của bạn. Bài viết “File Robots.txt là gì? Cách tạo tệp Robots.txt đơn giản nhất cho Website 2024” sẽ giải thích cụ thể cho bạn biết Robots.txt là gì và những thông tin xoay quanh nó.
Mục lục
Mục lục
1. File Robots.txt là gì?
File robots.txt là một tập tin văn bản đơn giản có dạng đuôi mở rộng txt. Tệp này là một phần của Robots Exclusion Protocol (REP) bao gồm một nhóm các tiêu chuẩn Web quy định cách Robot Web (hoặc Robot của các công cụ tìm kiếm) thu thập dữ liệu trên web, truy cập, index nội dung và cung cấp nội dung đó cho người dùng. Tệp robots.txt chủ yếu được dùng để quản lý lưu lượng truy cập của trình thu thập dữ liệu vào trang web của bạn và thường dùng để ẩn một tệp khỏi Google, tùy thuộc vào loại tệp.
2. Tại sao cần tạo file robots.txt?
Việc tạo file robots.txt cho website của mình giúp bạn kiểm soát được việc các bot của công cụ tìm kiếm ví dụ như Google thu thập thông tin trong các khu vực nhất định tại trang web. Tuy nhiên, khi tạo file bạn cần hết sức chú tâm vì nếu sai chỉ thị, các bot của Google có thể không thực hiện index cho website của bạn.
3. Cơ chế hoạt động của robots.tx?
Phương thức hoạt động của file robots.txt diễn ra như sau:
Bước 1: Crawl (phân tích) dữ liệu trên trang web để khám phá nội dung bằng cách đưa công cụ đi theo các liên kết từ trang này đến trang khác, sau đó thu thập dữ liệu thông qua hàng tỷ trang web khác nhau.
Quá trình crawl dữ liệu này còn được biết đến với tên khác là “Spidering”.
Bước 2: Index nội dung đó để đáp ứng yêu cầu cho các tìm kiếm của người dùng. File robots.txt sẽ chứa các thông tin về cách các công cụ của Google nhằm thu thập dữ liệu của website.
4. Cấu trúc của file Robots.txt
Lệnh Disallow
Tệp bắt đầu với dòng tiêu đề “User-agent: “, theo sau là tên của trình thu thập dữ liệu mà bạn muốn ngăn truy cập các trang web của mình. Sau đó, tệp có thể chứa một số dòng “Disallow: “, theo sau là URL của trang web mà bạn muốn ngăn bot truy cập. Ví dụ: nếu bạn muốn ngăn Googlebot truy cập trang web “/secret-page.html”, bạn có thể thêm dòng sau vào tệp robots.txt của mình: User-agent: Googlebot Disallow: /secret-page.html
Lệnh Allow
Bạn cũng có thể sử dụng tệp robots.txt để chỉ định các trang web mà bạn muốn trình thu thập dữ liệu ưu tiên truy cập. Để thực hiện việc này, hãy sử dụng cú pháp “Allow: “. Ví dụ: nếu bạn muốn Googlebot ưu tiên truy cập trang web “/home.html”, bạn có thể thêm dòng sau vào tệp robots.txt của mình: User-agent: Googlebot Allow: /home.html
Lệnh Sitemap
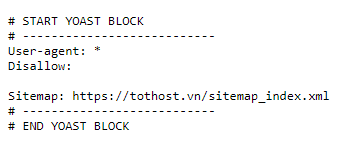
Sitemap là một tệp XML chứa thông tin về cấu trúc và liên kết của trang web để giúp các công cụ tìm kiếm hiểu rõ hơn về nội dung của trang web. Khi robot tìm thấy lệnh Sitemap trong robots.txt, nó sẽ truy cập vào tệp sitemap.xml để xem thông tin về cấu trúc trang web và các liên kết liên quan. Ví dụ, nếu bạn có một tệp sitemap.xml nằm ở đường dẫn “http://www.example.com/sitemap.xml”, bạn có thể thêm sitemap vào tệp robots.txt như sau: Sitemap: http://www.example.com/sitemap.xml Việc cung cấp tệp sitemap.xml trong tệp robots.txt giúp công cụ tìm kiếm như Googlebot hoặc Bingbot tìm thấy và khám phá nhanh chóng các trang trong trang web của bạn, đảm bảo rằng không có trang quan trọng bị bỏ sót trong quá trình thu thập thông tin.
Lệnh crawl-delay
Lệnh crawl-delay trong robots.txt là một chỉ thị cho bot của công cụ tìm kiếm đợi một khoảng thời gian nhất định trước khi thu thập dữ liệu một trang web. Điều này có thể hữu ích nếu bạn có một trang web lớn với nhiều trang và bạn muốn đảm bảo rằng trình thu thập dữ liệu không tải quá nhiều tài nguyên trên máy chủ của bạn. Cấu trúc của lệnh crawl-delay là: crawl-delay: <number> Trong đó <number> là số giây mà trình thu thập dữ liệu nên đợi trước khi thu thập dữ liệu trang tiếp theo. Ví dụ, với lệnh “crawl-delay: 10” sẽ khiến trình thu thập dữ liệu đợi 10 giây trước khi thu thập dữ liệu trang tiếp theo.
5. Những ưu điểm và hạn chế của tệp tin robots.txt
5.1. Ưu điểm
Việc tạo file robots.txt đem lại nhiều lợi ích cho website của bạn như:
Ngăn chặn nội dung trùng lặp (Duplicate Content) xuất hiện trong website.
Giữ một số phần của trang ở chế độ riêng tư.
Giữ các trang kết quả tìm kiếm nội bộ không hiển thị trên SERP.
Chỉ định vị trí của Sitemap.
Ngăn các công cụ của Google Index một số tệp nhất định trên trang web của bạn (hình ảnh, PDF, …)
Dùng lệnh Crawl-delay để cài đặt thời gian. Điều này sẽ ngăn việc máy chủ của bạn bị quá tải khi các trình thu thập dữ liệu tải nhiều nội dung cùng một lúc.
5.2. Hạn chế
Bên cạnh đó robots.txt cũng còn một số hạn chế nhất định:
Một số trình duyệt tìm kiếm không hỗ trợ các lệnh trong tệp robots.txt: Không phải công cụ tìm kiếm nào cũng sẽ hỗ trợ các lệnh trong tệp robots.txt, vậy nên để bảo mật dữ liệu, cách tốt nhất bạn nên làm là đặt mật khẩu cho các tệp riêng tư trên máy chủ.
Mỗi trình dữ liệu có cú pháp phân tích dữ liệu riêng: Thông thường đối với các trình dữ liệu uy tín sẽ tuân theo quy chuẩn của các lệnh trong tệp robots.txt. Nhưng mỗi trình tìm kiếm sẽ có cách giải trình dữ liệu khác nhau, một số trình sẽ không thể hiểu được câu lệnh cài trong tệp robots.txt. Vậy nên, các web developers phải nắm rõ cú pháp của từng công cụ thu thập dữ liệu trên website.
Bị tệp robots.txt chặn nhưng Google vẫn có thể index: Cho dù trước đó bạn đã chặn một URL trên website của mình nhưng URL đó vẫn còn xuất hiện thì lúc này Google vẫn có thể Crawl và index cho URL đó của bạn.
6. Cách kiểm tra file Robots.txt trang web của bạn
Thêm đuôi “/robots.txt” vào địa chỉ URL
Ví dụ robots.txt
Một cách là sử dụng trình duyệt web của bạn. Để thực hiện việc này, hãy nhập URL của trang web vào thanh địa chỉ của trình duyệt web của bạn và nhấn Enter. Sau đó, hãy nhập “/robots.txt” vào thanh địa chỉ của trình duyệt web của bạn và nhấn Enter. Nếu tệp robots.txt tồn tại, trình duyệt web của bạn sẽ hiển thị nội dung của nó.
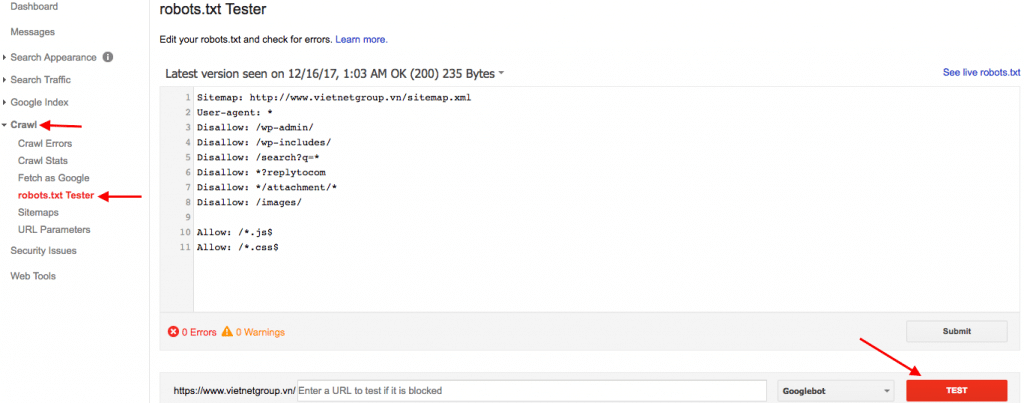
Sử dụng Trình kiểm tra robots.txt
Một cách khác để xem website đã có tệp robots.txt hay chưa là sử dụng Trình kiểm tra robots.txt. Với trình duyệt Google, bạn có thể sử dụng Trình kiểm tra robots.txt trực tuyến. Điều kiện để sử dụng công cụ trực tuyến này là bạn phải liên kết website của mình với Google Search Console.
Tại mục Crawl, nhấn vào robots.txt Tester và chọn nút TEST.
Cách tạo tệp Robots.txt cho Website đơn giản nhất
Cách 1: Sử dụng công cụ Yoast SEO
Bước 1: Đăng nhập vào website của bạn trên WordPress, khi đăng nhập vào sẽ thấy giao diện của trang WordPress Dashboard.
Bước 2: Chọn mục SEO > Chọn Tools.
Bước 3: Chọn File editor. Sau đó bạn sẽ thấy mục robots.txt và .haccess, chọn Creat robots.txt file và chờ tệp được khởi tạo.
Cách 2: Qua bộ Plugin All in One SEO
Để tạo file robots.txt WordPress, bạn có thể thực hiện theo các bước sau:
Bước 1: Truy cập giao diện chính của Plugin All in One SEO Pack.
Bước 2: Chọn All in One SEO > Chọn Feature Manager > Nhấp Activate cho mục Robots.txt.
Bước 3: Tạo lập và điều chỉnh file robots.txt WordPress.
Lời kết
Hi vọng bài viết đã được cung cấp những kiến thức đầy đủ về loại file vô cùng quan trọng với các website. Mong rằng với những thông tin đã được đưa ra sẽ giúp bạn hiểu được tầm quan trọng của nó và tối ưu hóa được chất lượng của website của chính mình. Đọc thêm các bài viết liên quan:
Khi bạn click vào một bài viết, chốt thành công một đơn hàng trên Shopee hay đăng nhập vào Facebook, mọi thứ dường như diễn ra mượt mà chỉ trong chớp mắt. Thế nhưng, ẩn sau giao diện bóng bẩy đó là một hệ thống xử lý dữ liệu khổng lồ đang hoạt động hết công suất. Thế giới Web hiện đại được vận hành dựa trên sự giao tiếp liên tục của hai "bán cầu": Server-side (phía máy chủ) và Client-side (phía máy khách). Bài viết này sẽ giúp bạn giải mã Server-side là gì, cũng như hiểu rõ sự khác biệt mang tính "sống còn" giữa hai đầu cầu này trong quy trình phát triển và tối ưu Website.
Bất kể bạn đang vận hành một website doanh nghiệp, một hệ thống app nội bộ hay đang cắm tool MMO, rủi ro mất dữ liệu luôn hiện hữu. Máy chủ có thể bị tấn công Ransomware, lỗi cấu hình phần mềm, hoặc đơn giản nhất là... bạn lỡ tay gõ nhầm lệnh xóa. Việc sao lưu (Backup) dữ liệu định kỳ là chiếc phao cứu sinh duy nhất. Bài viết này sẽ hướng dẫn bạn chi tiết từ A-Z cách Backup và Restore dữ liệu trên cả VPS Linux và VPS Windows, cùng những lưu ý "sống còn" dành riêng cho khách hàng sử dụng dịch vụ tại TotHost.
Trong bối cảnh không gian địa chỉ IPv4 ngày càng cạn kiệt, làm thế nào để hàng tỷ thiết bị trên toàn cầu có thể kết nối Internet một cách thông suốt và an toàn? Câu trả lời nằm ở NAT (Network Address Translation) – một công nghệ định tuyến "xương sống" không thể thiếu trong bất kỳ hệ thống mạng máy tính hay hạ tầng máy chủ nào hiện nay. Vậy thực chất NAT là gì? Công nghệ này vận hành ra sao và bao gồm những chuẩn phân loại nào? Bài viết dưới đây sẽ giúp bạn giải mã chi tiết toàn bộ các khái niệm, nhiệm vụ cốt lõi và những thuật ngữ kỹ thuật quan trọng nhất liên quan đến NAT.
Hiện nay, các dịch vụ điện toán đám mây dần trở nên phổ biến với mọi Doanh Nghiệp. Chính vì vậy, ngày càng xuất hiện nhiều lựa chọn đa dạng hơn như: Public Cloud, Private Cloud, Hybrid Cloud. Trong nội dung bài viết này, Tothost sẽ giải thích chi tiết Hybrid Cloud là gì cùng những lợi ích khi sử dụng mô hình này. Hãy cùng theo dõi nhé!
CloudFlare không còn là cái tên xa lạ đối với các quản trị viên website. Nó giúp cho website tăng tốc độ truy cập, mang đến sự bảo mật cao, và tiết kiệm băng thông cho máy chủ. Vậy, thực chất CloudFlare là gì? Thiết lập và cài đặt CloudFlare như thế nào?
Cho dù bạn có biết đến các thuật ngữ như Cloud, Cloud storage, Cloud computing hay không. Thì mỗi ngày, mỗi giờ, bạn vẫn đang tiếp xúc với chúng một cách vô thức. Những khái niệm tưởng chừng xa lạ nhưng lại gắn liền với đời sống thường nhật của bạn. Vậy, chính xác Cloud storage là gì? Chúng vận hành ra sao, ảnh hưởng thế nào đến cuộc sống của chúng ta? Bạn hãy cùng TotHost tìm hiểu qua bài viết sau nhé!